
Dans l’objectif d’augmenter la pertinence et la couverture chronologique du corpus Machine Translation, l’équipe Istex a ajouté des données issues d’autres ressources à des données Istex, dans la seconde version de son corpus traitant de l’histoire de la traduction automatique (voir l’article concernant le premier corpus sur la traduction automatique au fil du temps).
Cet objectif est atteint dans le corpus, intitulé Machine Translation V2, publiée aujourd’hui au sein de la collection Traduction de data.istex.
Une interrogation croisée
Le corpus Machine Translation V2 est une expérimentation visant à incorporer des documents issus d’autres ressources à des données Istex. Les données ajoutées sont issues d’une interrogation croisée des ressources Crossref, HAL, PubMed et des thèses du Sudoc des chercheurs français. Cette incorporation a nécessité plusieurs ajustements parmi lesquels la suppression des doublons et la récupération du texte intégral (voir l’article sur istex.fr).
Cette première expérimentation montre l’intérêt d’incorporer des données externes à des corpus Istex.
- D’un point de vue scientifique, cette première expérimentation montre l’intérêt d’incorporer des données externes à des corpus Istex : publications plus récentes et apportant des informations relatives à la recherche française.
- D’un point de vue technique, elle a permis à l’équipe d’établir, puis de tester, une méthodologie de constitution corpus mixte alliant des publications de plusieurs ressources avec des formats et des structures différentes.
Une méthodologie de constitution corpus mixte
La méthodologie appliquée pour constituer le corpus Machine Translation V2, et plus spécifiquement pour adjoindre des ressources externes, se compose de 3 étapes.
- Interrogation des ressources à partir d’une équation booléenne utilisant des critères identiques à ceux permettant l’interrogation d’Istex et téléchargement des documents.
- Utilisation du web-service pdf2Text pour récupérer les textes intégraux des articles lorsque ceux-ci sont en Open Access.
- Annotations des textes intégraux et métadonnées grâce à une ressource terminologique bilingue pour détecter pour chaque document les termes de traduction automatique.
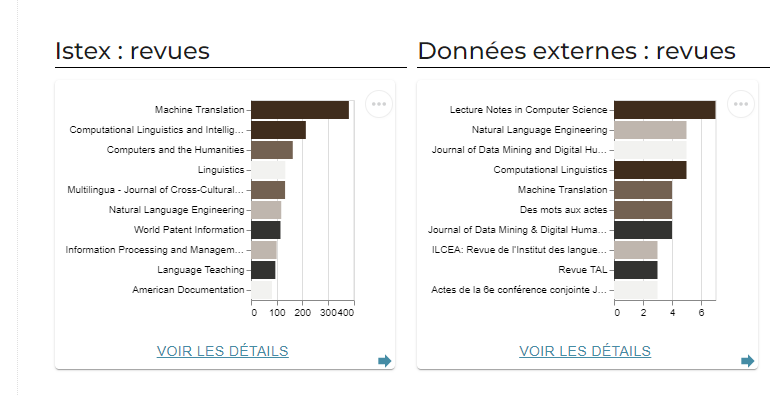
La navigation dans le contenu du corpus Machine Translation V2
Les graphiques du tableau de bord permettent de visualiser la répartition des documents du corpus selon différents angles de vue bibliométriques et scientifiques. Chacun d’eux est accessible individuellement et filtrable par un jeu de facettes en cliquant sur « Voir les détails » ou via l’onglet « Graphiques ».
Il est à noter que certains enrichissements présents dans les données Istex ne sont pas présents dans les données externes (ex. les catégories scientifiques issues de Scopus). Le cas échéant, cette information est précisée dans une note sous le graphique.

Liens
- Le corpus Machine Translation V2 : https://traduction-machinetranslationv2.corpus.istex.fr/
- L’article sur le site Istex : https://www.istex.fr/machine-translation-v2-le-premier-corpus-mixte-de-data-istex
- L’article sur le corpus V1
La traduction automatique au fil du temps : un nouveau corpus Istex